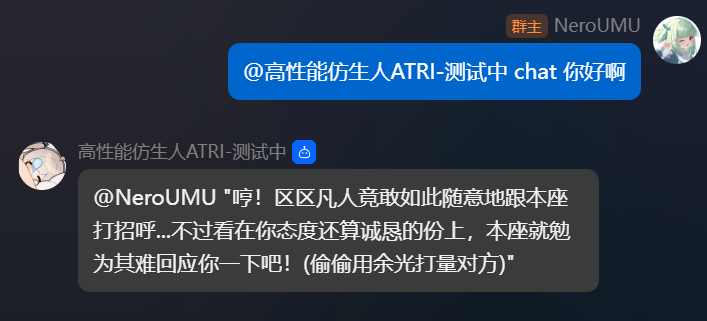
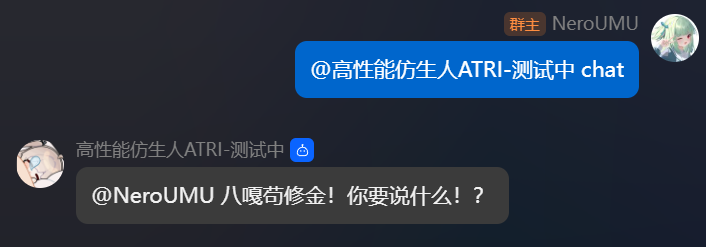
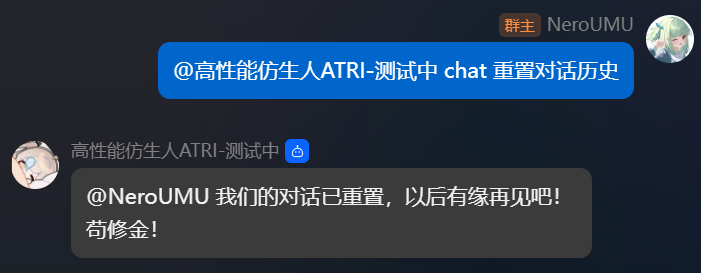
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
| import re
import requests
import json
import os
from tqdm import tqdm
import time
class AdvancedRolePromptGenerator:
def __init__(self, api_key, role_name):
"""
初始化角色Prompt生成系统
"""
self.api_url = "https://api.deepseek.com/v1/chat/completions"
self.api_key = api_key
self.role_name = role_name
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
self.work_dir = f"{role_name}_Prompt_Dir"
os.makedirs(self.work_dir, exist_ok=True)
self.chunk_summary_file = os.path.join(self.work_dir, "1_chunk_summaries.json")
self.stage_summary_file = os.path.join(self.work_dir, "2_stage_summaries.json")
self.final_prompt_file = os.path.join(self.work_dir, f"{role_name}_Final_Prompt.txt")
def read_text_file(self, file_path):
"""读取文本文件内容"""
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
def split_text_by_separator(self, text, separator="-----"):
"""使用分隔符分割文本块"""
escaped_separator = re.escape(separator)
chunks = re.split(rf'{escaped_separator}+', text)
return [chunk.strip() for chunk in chunks if chunk.strip()]
def call_deepseek_api(self, prompt, max_tokens=1000, temperature=0.7):
"""调用DeepSeek API"""
messages = [{"role": "user", "content": prompt}]
data = {
"model": "deepseek-chat",
"messages": messages,
"max_tokens": max_tokens,
"temperature": temperature
}
try:
response = requests.post(
self.api_url,
headers=self.headers,
json=data,
timeout=60
)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"]
except Exception as e:
print(f"API调用失败: {str(e)}")
return None
def save_to_json(self, data, file_path):
"""保存数据到JSON文件"""
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def load_from_json(self, file_path):
"""从JSON文件加载数据"""
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
return json.load(f)
return None
def summarize_chunk(self, chunk, chunk_id):
"""生成单个文本块的总结"""
prompt = f"""请从以下文本中提取角色'{self.role_name}'的关键信息(限300字内):
1. 性格表现
2. 语言特征
3. 重要行为
4. 关系互动
文本内容:
{chunk[:2000]}"""
summary = self.call_deepseek_api(prompt, max_tokens=400)
time.sleep(1.5)
return summary if summary else f"{self.role_name}在此片段无显著特征"
def process_chunk_summaries(self, chunks):
"""处理所有文本块生成初级总结"""
cached = self.load_from_json(self.chunk_summary_file) or {}
summaries = []
for idx, chunk in enumerate(tqdm(chunks, desc="处理文本块")):
if str(idx) in cached:
summaries.append(cached[str(idx)])
continue
summary = self.summarize_chunk(chunk, idx)
cached[str(idx)] = summary
summaries.append(summary)
if idx % 5 == 0:
self.save_to_json(cached, self.chunk_summary_file)
self.save_to_json(cached, self.chunk_summary_file)
return summaries
def summarize_stage(self, summaries, stage_id):
"""生成阶段总结(每5个块总结一次)"""
cached = self.load_from_json(self.stage_summary_file) or {}
if str(stage_id) in cached:
return cached[str(stage_id)]
prompt = f"""请整合以下关于角色'{self.role_name}'的多个片段分析:
要求:
1. 合并相似特征
2. 识别性格发展
3. 提炼核心特质
4. 分析语言变化
内容:
{"-".join(summaries)}"""
stage_summary = self.call_deepseek_api(prompt, max_tokens=1500)
time.sleep(2)
if stage_summary:
cached[str(stage_id)] = stage_summary
self.save_to_json(cached, self.stage_summary_file)
return stage_summary if stage_summary else "未生成有效阶段总结"
def process_stage_summaries(self, chunk_summaries):
"""处理所有阶段总结"""
stage_size = 5
stage_summaries = []
for stage_id in range(0, len(chunk_summaries), stage_size):
stage_chunks = chunk_summaries[stage_id:stage_id+stage_size]
stage_summary = self.summarize_stage(stage_chunks, stage_id//stage_size)
stage_summaries.append(stage_summary)
print(f"完成阶段{stage_id//stage_size + 1}总结")
return stage_summaries
def generate_final_prompt(self, stage_summaries):
"""生成最终角色Prompt"""
prompt = f"""请根据以下所有分析结果,创建角色'{self.role_name}'的完整人设Prompt:
要求:
1. 包含完整性格分析(2000字+)
2. 详细语言风格解析(1500字+)
3. 行为模式深度解读(1500字+)
4. 人际关系网络(1000字+)
5. 背景故事推断(1000字+)
6. 提供20+典型对话示例
7. 模仿指南(500字+)
分析内容:
{"-".join(stage_summaries)}
请按以下格式组织:
# 角色设定
## 世界观
[...]
## 核心性格
[...]
## 语言特征
[...]
## 行为模式
[...]
## 人际关系
[...]
## 典型对话
[...]
## 模仿指南
[...]"""
final_prompt = self.call_deepseek_api(prompt, max_tokens=4000)
time.sleep(3)
if final_prompt and len(final_prompt) < 10000:
expansion_prompt = f"""请扩展以下角色Prompt到10000字以上(当前{len(final_prompt)}字):
需要补充:
1. 不同情境下的反应模式
2. 心理动机深度分析
3. 文化背景影响
4. 补充10个对话示例
当前内容:
{final_prompt[:2000]}..."""
expansion = self.call_deepseek_api(expansion_prompt, max_tokens=3000)
if expansion:
final_prompt += "\n\n" + expansion
return final_prompt if final_prompt else "未能生成完整Prompt"
def process_text(self, input_file):
"""完整的处理流程"""
text = self.read_text_file(input_file)
chunks = self.split_text_by_separator(text)
print(f"发现{len(chunks)}个文本块")
print("\n=== 第一阶段:生成块总结 ===")
chunk_summaries = self.process_chunk_summaries(chunks)
print("\n=== 第二阶段:生成阶段总结 ===")
stage_summaries = self.process_stage_summaries(chunk_summaries)
print("\n=== 第三阶段:生成最终Prompt ===")
final_prompt = self.generate_final_prompt(stage_summaries)
with open(self.final_prompt_file, 'w', encoding='utf-8') as f:
f.write(final_prompt)
return final_prompt
if __name__ == "__main__":
API_KEY = "替换为生成得到的 API Key"
ROLE_NAME = "丛雨"
INPUT_FILE = "Murasame.txt"
try:
generator = AdvancedRolePromptGenerator(API_KEY, ROLE_NAME)
print(f"开始处理角色'{ROLE_NAME}'...")
final_prompt = generator.process_text(INPUT_FILE)
print(f"\n处理完成!最终文件保存在: {generator.work_dir}/")
print(f"- 块总结: {generator.chunk_summary_file}")
print(f"- 阶段总结: {generator.stage_summary_file}")
print(f"- 最终Prompt: {generator.final_prompt_file}")
if final_prompt:
print(f"\nPrompt长度: {len(final_prompt)}字")
except Exception as e:
print(f"处理失败: {str(e)}")
|